모두의 딥러닝 lec12~
sequence data :
하나의 단어만 들었다고 그 문장의 의미가 다 이해되는 것이 아니고, 이전의 단어를 이해하고 그 다음 단어를 들었을 때 이해하게 되는 것. = 사람의 말, 자연어
이처럼 이전의 데이터가 그 다음의 데이터에 영향을 주는 것을 의미한다.
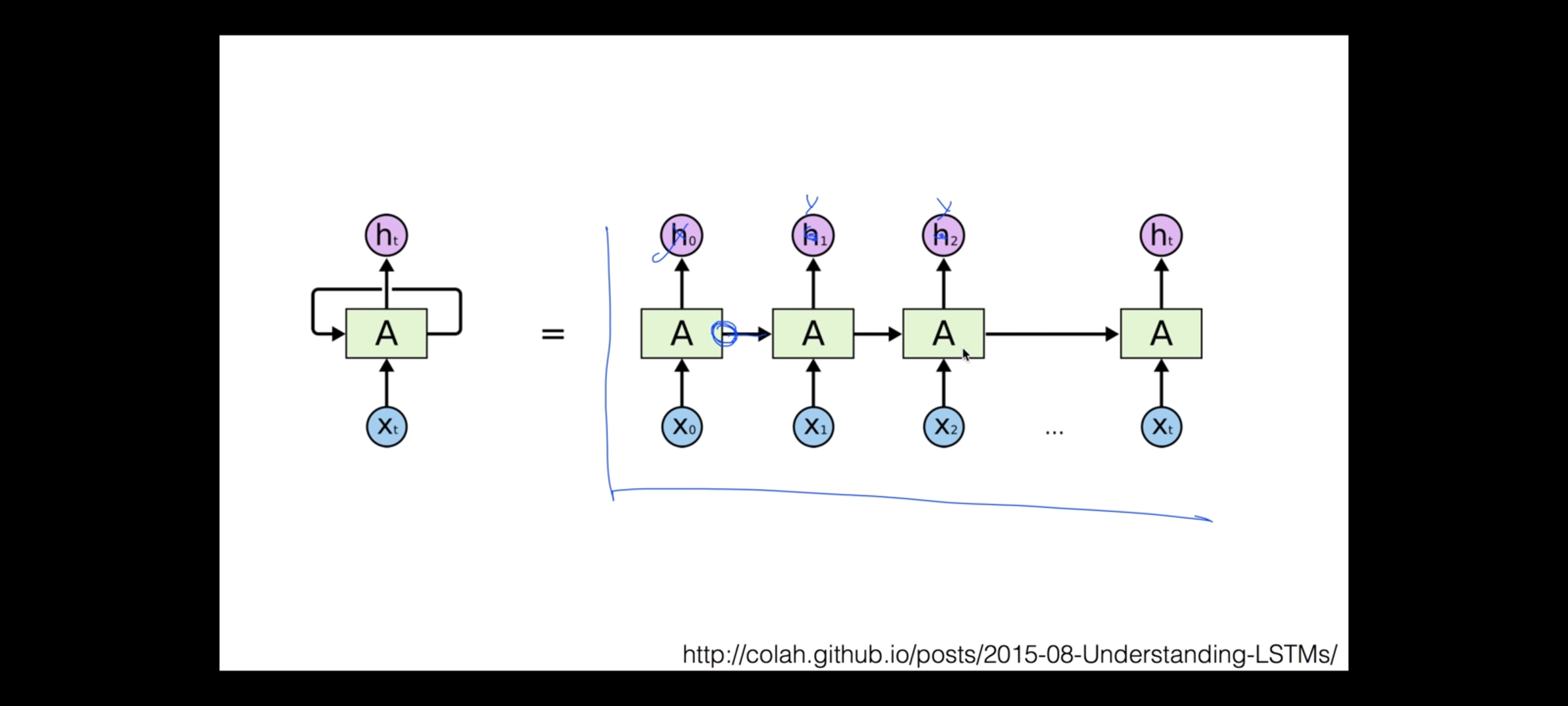
시리즈 결과에 굉장히 적합한 모델.
A를 구성하는데3개의 W가 구성됨. Wh, Wz, Wy 각 셀에 같은 W 로 학습을 하고, 똑같은 값을 추출한다.
입력값을 자연어로 줄 때 (ex. hello) RNN 로 표현하는 방법:
단어 4개에 값에 해당하는 위치에 1을 넣어 베타를 표현함.
각 LAYER에서 input layer + hidden layer 한 후 다음 칸에 영향을 준다. 마지막으로 y 를 뽑아낼 때
실제 값들과 원하는 자리가 같지 않을 때 , cost 함수는 어떻게 계산 할 것인가? 이전에 배웠던 softmax 함수을 사용한다.
이렇게 학습이 되면 그 후 한 글자는 뭐가 되겠다 예측이 가능!
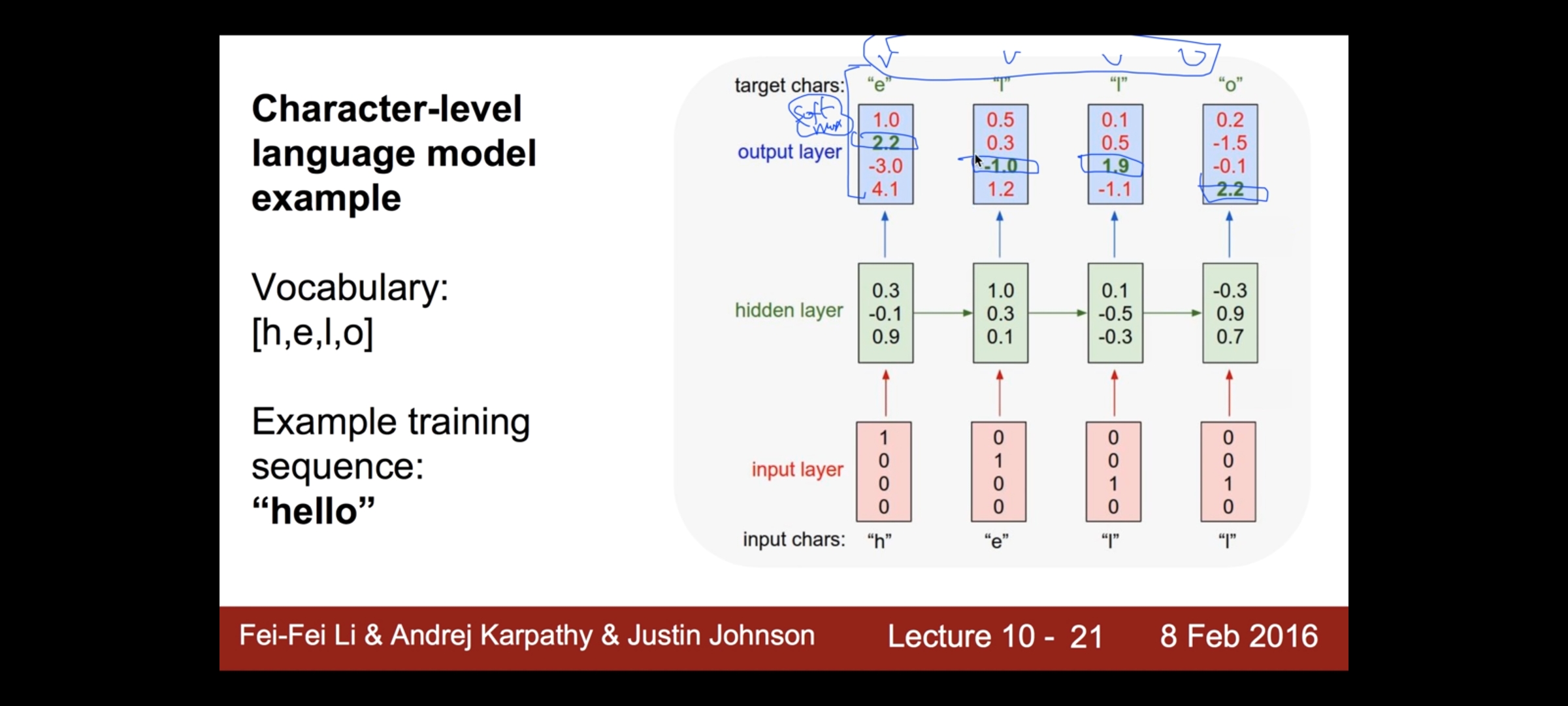
이런 형태의 RNN 활용하는 곳 :
Language Modeling, speech Recognition, Machine Translation, Conversion Modeling/Questions Answering 등등..
rnn 은 종류가 아주 다양해 어떻게 활용하느냐에 따라 달라진다. 이미지 캡션같은 경우 - one to many 로 ( ex. 나는 모자를 쓰고있네.) Image Caption 등 만들 수 있다.
mamy to many - 비디오 프레임은 사진이 하나가 아니니까 여러개의 이미지를 받고 각각의 프레임을 설명하는 것으로 받을 수 있다. 다이나믹 함수를 사용해 우리가 만든 셀을 넘겨준다.
RNN TansorFlow))
1. 첫번째의 셀을 만든다. (셀에서 나가는 아웃풋의 크기를 정해주는 것이 중요.)
2. 만든 것을 실제로 구동을 시킨다. 그럼 이 드라이브는 하나는 아웃풋 출력을 내고 하나는 마지막의 스테이트 값을 낸다! 그 이유는 셀을 생성시키는 부분과 셀을 가지고 학습하고 구동하는 부분을 나눠줌으로서 우리가 원하는 형태의 셀을 마음대로 바꿀 수 있게 한다.

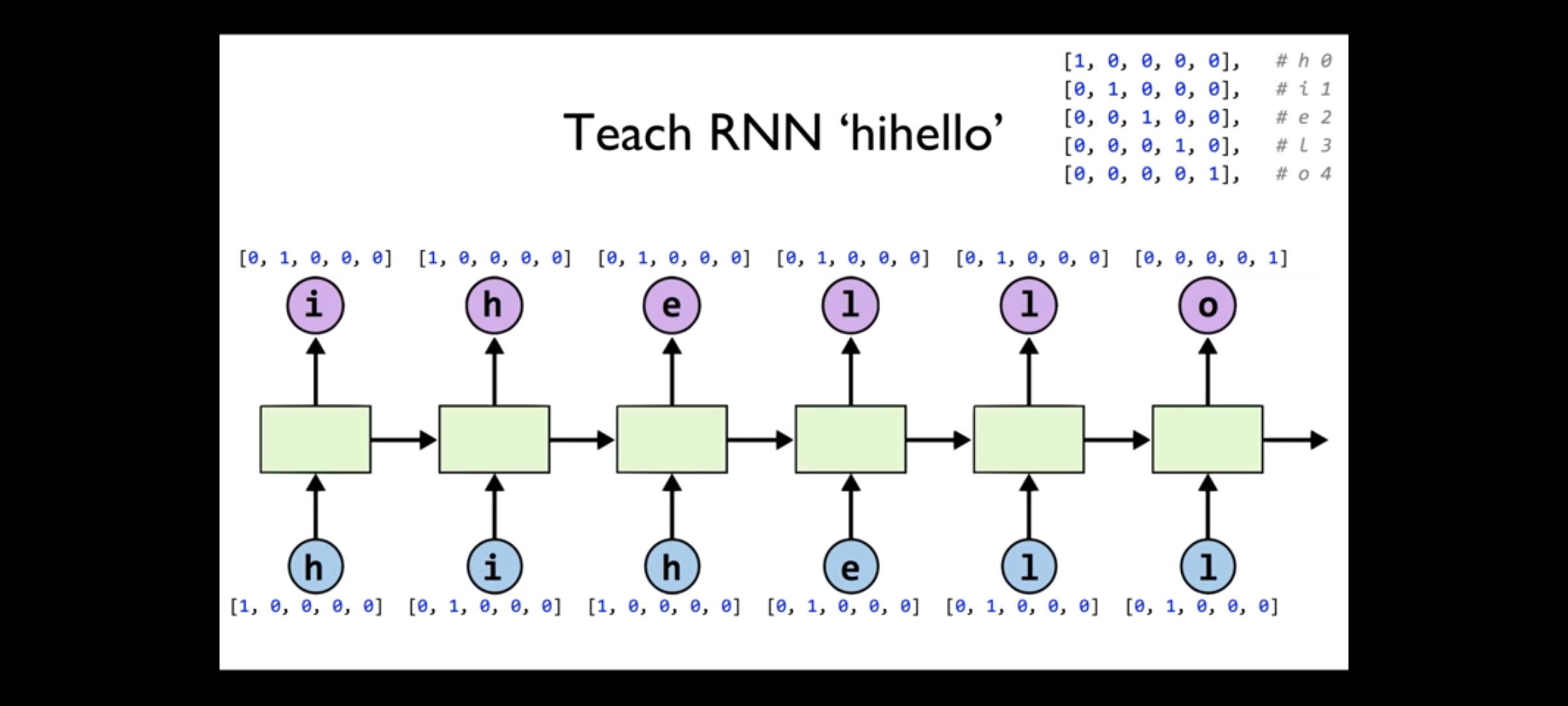
hihello RNN 훈련시키기! (내가 한 문자를 주면 다음 문자를 무엇인지 예측하게 하기.)
unique chars - 5개. 문자열을 원핫 인코딩으로 바꾸는 과정을 통해 문자는 숫자로, 숫자는 문자로 바꾸기
'AI 스터디 내용 > ML , DL' 카테고리의 다른 글
| 6주차 - 과적합 (0) | 2021.02.26 |
|---|---|
| 5주차 - 역전파 (0) | 2021.02.26 |
| 4주차 - AF (0) | 2021.02.26 |
| 3주차 Sigmoid (0) | 2021.02.26 |
| 2주차 - Gradient descent (0) | 2021.02.26 |


