아파치 카프카 애플리케이션 프로그래밍 책을 본 후 필요에 맞게 변형하여 정리한 내용입니다.
1. 싱글 브로커로 구성된 카프카 클러스터
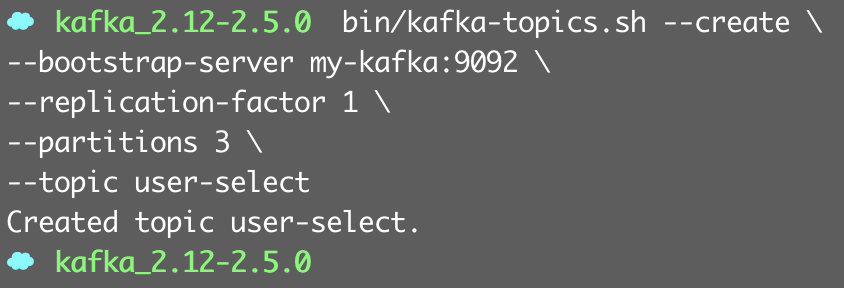
상용 파이프라인 아키텍처에 적용하는 것을 고려하면 복제 개수를 2로 잡아야 하지만,
싱글 브로커로 구성된 카프카 클러스터를 사용하므로 최대 복제 가능 개수 값인 1로 설정.
2. 간단한 웹 페이지 개발


- 버튼을 클릭했을 때 웹 이벤트를 프로듀서로 전송하기 위해 jQuery, Ajax를 사용하여 비동기 호출 코드 생성
- 이름 입력하지 않으면 "이름을 입력하세요" 내용의 alert 창을 띄운다.
input 태그에 이름이 포함되는 경우 프로듀서 애플리케이션으로 사용할 url 인 localhost:8080에 GET 호출 수행
/api/select로 REST API 를 받을 수 있도록 프로듀서 애플리케이션에서 작성.
GET 호출과 함께 service, user 파라미터로 웹 이벤트 값을 전달한다.
3. REST API 프로듀서 개발
spring boot, spring 카프카 기반으로 개발
- 스프링 부트 기반 애플리케이션 개발 위해 gradle에 라이브러리 추가
(spring-kafka : kafka Template 을 프로듀서로 사용,
spring-boot-starter-web : REST API를 구현하기 위한 RestController 사용
gson : 자바 객체를 JSON포맷의 String 타입으로 변환)
(1) REST API를 받을 자바 코드 작성
- application.yml : 스프링 부트에서 사용할 리소스를 사람이 쉽게 읽을 수 있는 형태로 만든 설정 파일
스프링 카프카에서 사용하는 클러스터 정보, 직렬화 방식, 옵션들 설정
-ProduceController.java / RestApiProducer.java 생성
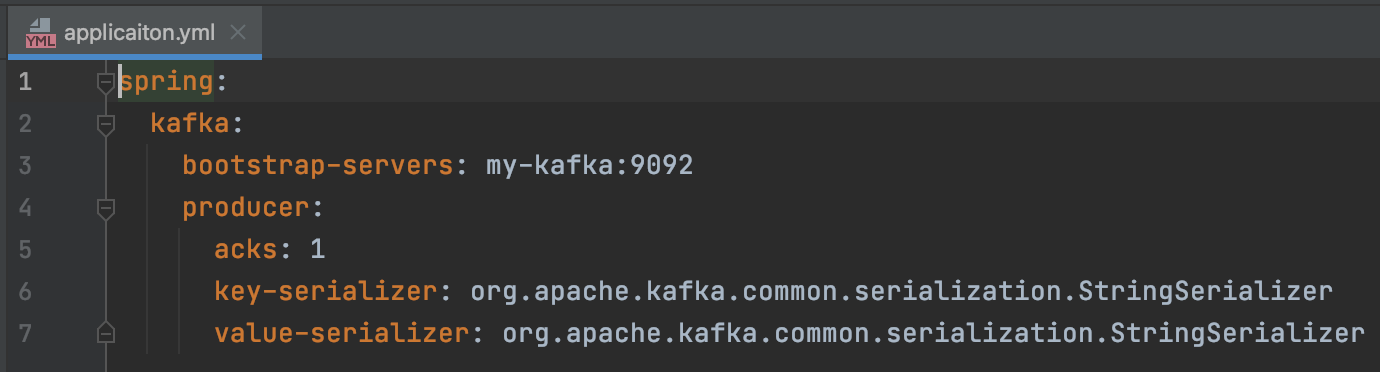
프로듀서의 acks, 메시지 키 직렬화, 메시지 값 직렬화 선언
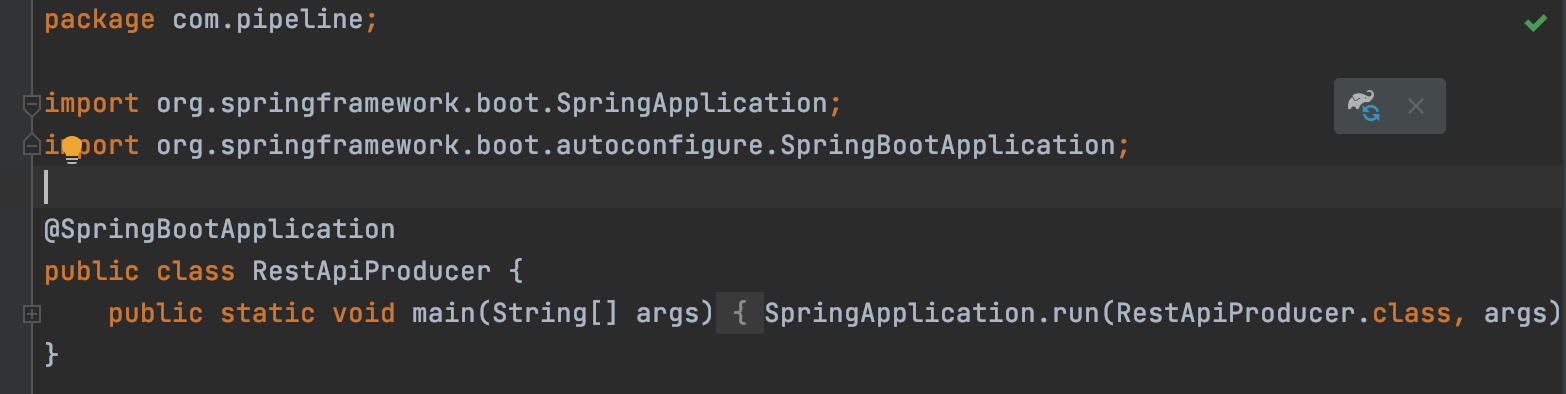
스프링 부트 실행 애플리케이션 선언 위해 @SpringBootApplication 어노테이션 포함된 실행 클래스 생성.
public static void main에서 SpringApplication.rum() 메소드 호출함으로써 스프링 부트를 실행할 수 있다.
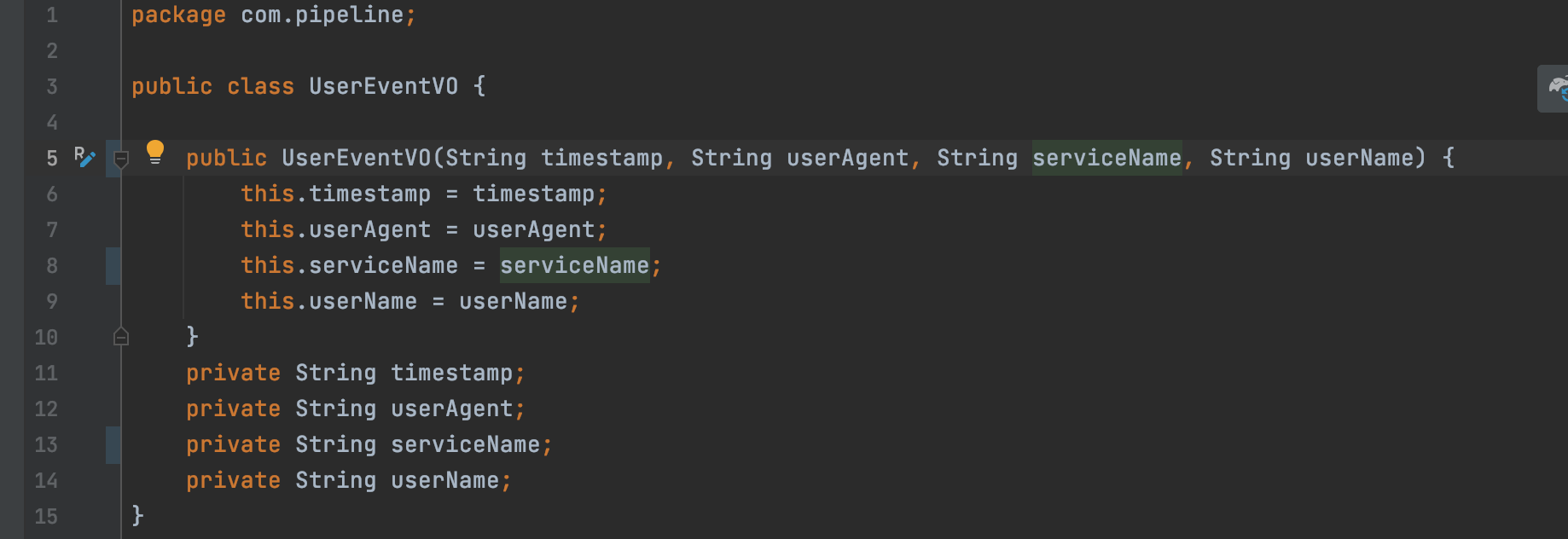
사용자 웹 이벤트를 객체로 받기 위해 VO 형태로 클래스 작성.
timestamp : REST API를 호출받은 시점을 메시지 값에 넣는 역할
이 값을 변수에 넣으면 컨슈머에서 병렬처리되어
적재 시점이 달라지더라도 최종 적재된 데이터의 timestamp 값을 기준으로 호출시간 정렬 가능!!
userAgent : REST API를 호출받을 때 받을 수 있는 사용자 브라우저 종류.

실질적으로 REST API를 받는 역할을 하는 클래스
(2) 하둡 적재 컨슈머 애플리케이션 개발
컨슈머 애플리케이션 개발 전 어떤 스레드 전략으로 데이터를 적재할지 정하고 시작해야 함.
하둡에 데이터를 적재하는 컨슈머 애플리케이션은 하둡과 카프카 클라이언트 라이브러리를 기반으로 개발한다.
하둡과 연동하기 위해 필요한 라이브러리
slf4j-simple : 로그 작성
kafka-clients : 카프카 컨슈머 API 사용
hadoop-client : 하둡 연동 API 사용
컨슈머 스레드들을 실행하는 자바 main 스레드. 컨슈머에 필요한 설정을 미리 정의해서 각 컨슈머 스레드에 Properties 인스턴스를 넘긴다.
컨슈머의 안전한 종료를 위한 셧다운 훅 로직이 포함된다.
ConsumerWorker : HdfsSinkApplication에서 전달받은 Properties 인스턴스로 컨슈머를 생성, 실행하는 스레드 클래스.
토픽에서 데이터를 받아 HDFS에 메시지 값들을 저장한다.
어떤 방식으로 데이터를 적재하느냐는 데이터를 최종 적재하는 타깃 애플리케이션이 기능 지원 여부에 따라 다르다. (HDFS는 flush, append 둘 다 지원 가능)
나는 HDFS에 flush 방식을 사용하여 데이터를 적재하는 로직 적용
- flush 방식 : 시간 또는 개수를 기준으로 데이터를 저장. 여기서는 개수를 기준으로 버퍼에 쌓인 데이터가 10개가 넘은 경우 데이터 저장하도록 함.
컨슈머 멀티 스레드 환경은 동일 데이터의 동시 접근에 유의해야 한다. 여러 개의 컨슈머가 동일한 HDFS 파일에 접근을 시도한다면 교착 상태에 빠질 수 있는 위험이 있기 때문이다.
교착상태 : ( 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태 )
이를 위해 어떤 로직으로 HDFS에 데이터를 저장할지 생각해야 함.
가장 간단하면서도 명확한 방법은 파티션 번호에 따라 HDFS 파일을 따로 저장하는 것이다.
1개의 컨슈머 스레드는 1개 이상의 파티션에 할당된다. 해당 컨슈머 스레드에 할당된 파티션을 assignment() 메서드를 통해 확인하고 데이터들을 각 파티션 번호를 붙인 파일에 저장한다.
기능 테스트
위에서 사용자의 웹 이벤트를 수집하는 파이프라인을 만들기 위해 토픽을 생성했고, 프로듀서, 컨슈머, 커넥터까지 개발했다.
개발된 코드들을 로컬 개발환경에서 실행하기 위해
1. REST 프로듀서 실행
2. 하둡 적재 컨슈머 실행
'Data Engineering > Kafka' 카테고리의 다른 글
| Kafka Connector 설정 / 시작 (PostgreSQL Debezuim) (0) | 2024.10.14 |
|---|---|
| PostgreSQL CDC (2) - Kafka Debezium (2) | 2024.10.14 |
| 카프카 스트림즈, 토폴로지 (0) | 2021.07.20 |
| 메시지 키가 지정된 데이터 전송 프로듀서 (0) | 2021.07.19 |
| 프로듀서 중요 개념 (0) | 2021.07.18 |