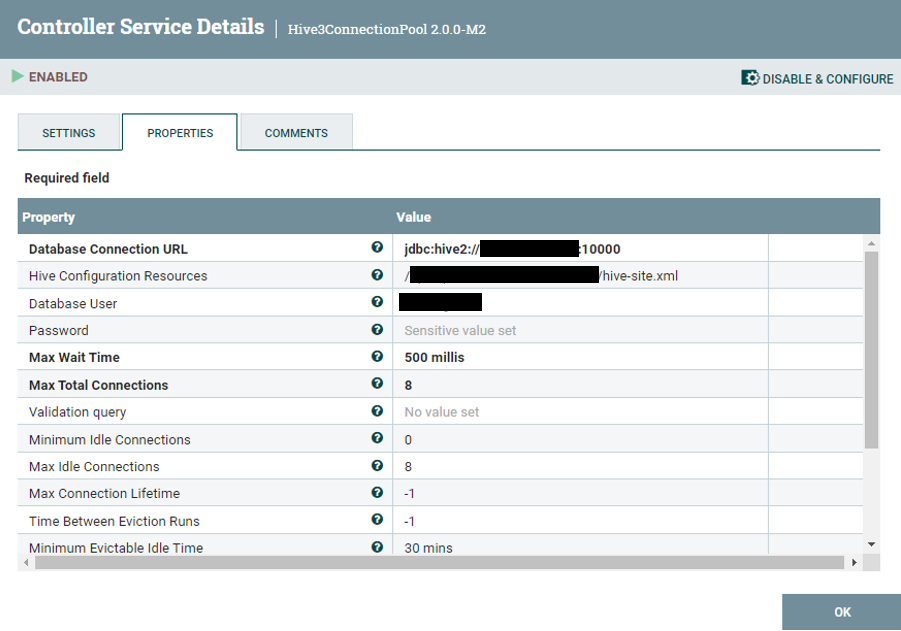
trino 를 통해 select ~ from ~ order by 쿼리 실행 시 문제가 없지만,
insert 할 때 insert ~ select ~ order by 실행 시 error 는 안나지만,
sorting 이 정상적으로 실행되지않는 현상을 발견했다.
찾아보니, trino 가 하위 쿼리의 order by 를 무시하고 (sorting 미지원) 쿼리를 실행한다!
참조 :
https://trino.io/blog/2019/06/03/redundant-order-by.html
Removing redundant ORDER BY
Optimizers are all about doing work in the most cost-effective manner and avoiding unnecessary work. Some SQL constructs such as ORDER BY do not affect query results in many situations, and can negatively affect performance unless the optimizer is smart en
trino.io
https://stackoverflow.com/questions/64901686/why-is-order-by-not-working-in-a-presto-query
Why is ORDER BY not working in a Presto query?
I have a fairly simple Presto query, that is not ORDERing by the column I specified: (SELECT tag_monitor_domains.property_name, count(*) as HourCount FROM pageviews INNER JOIN tag_monitor_do...
stackoverflow.com
'Data Engineering > Trino' 카테고리의 다른 글
| [Trouble Shooting] Trino 클러스터가 2대 이상일 때, TLS 적용 (0) | 2024.04.23 |
|---|---|
| [Trouble Shooting] trino cli > not working on linux ppc64le (0) | 2024.04.09 |