vi workers
hadoop 1인가? 에서 master 도 있었다는데
지금은 없음.
원래 데이터노드만 적어야 하는데
/home/hadoop/etc/hadoop/core-site.xml
- 클러스터 내의 네임노드에서 실행되는 하둡 데몬에 관한 설정
-�로그파일, 네트워크 튜닝, I/O튜닝, 파일 시스템 튜닝, 압축 등 하부 시스템 설정 파일
- HDFS(hdfs-site.xml)와 맵리듀스(mapred-site.xml)에서 공통적으로 사용할 환경정보 설정
-�만약 core-site.xml 이 없을 경우 core-default.xml 에 있는 기본값을 사용한다.
vi core-site.xml
HDFS와 맵리듀스에서 공통적으로 사용할 환경 정보 설정
fs.defaultFS
- hdfs의 기본 이름.
hdfs dfs -ls 명령어 가능하게 하기 위해 쓴다 !
만약 안쓴다면 hdfs dfs -ls hdfs://HA ~... 이렇게 써야할 것이다. 참으로 귀찮은 일이 아닐 수 없다.
- URI 형태
- 데이터 노드는 여러 작업을 진행하기 위해 반드시 네임노드의 주소를 알아야 함
ha.zookeeper.quorum
- 주키퍼 HA 구성시 사용
- 구성 갯수는 3, 5, 7과 같은 홀수개로 구성
( 짝수개여도 문제는 없지만, 장애 발생 시 과반수 이상이 동의해야 중단되어야 하는데 짝수는 의미가 없기 때문이다. )
( 참고 : https://paulsmooth.tistory.com/156 )
- 주키퍼 설정파일에서 포트를 2181로 설정하지 않았으면 설정한 포트로 수정할 것
< 다른 옵션 >
fs.default.name
- hdfs-site.xml 에서 설정한 하둡 클러스터의 이름으로 설정
hadoop.tmp.dir
- hdfs와 yarn이 사용할 임시 디렉토리
- 하둡에서 발생하는 임시 데이터를 저장하기 위한 공간
- 디폴트로 /root/tmp 에 데이터를 생성함
네임노드, 보조 네임노드, 데이터노드 등과 같은
- dfs.namenode.name.dir : 네임노드가 영속적인 메타데이터를 저장할 디렉토리 목록을 지정한다. 네임노드는 메타데이터의 복제본을 목록에 디렉토리별로 지정한다.
- dfs.datanode.name.dir : 데이터노드가 블록을 저장할 디렉토리의 목록. 각 블록은 이 디렉터리 중 오직 한 곳에서만 저장한다.
타입
서버
포트
종류
사용법
설명
hdfs
hdfs
8020
RPC
hadoop fs -ls hdfs://$(hostname -f):8020/
네임노드 호출
hdfs
webhdfs
50070
http
curl -s http://$(hostname -f):50070/webhdfs/v1/?op=GETFILESTATUS
jq
9870
마스터노드 웹 UI
참고 : https://velog.io/@anjinwoong/Hadoop
[Hadoop] Hadoop 서비스 포트 정리
Hadoop 서비스 포트 정리
velog.io
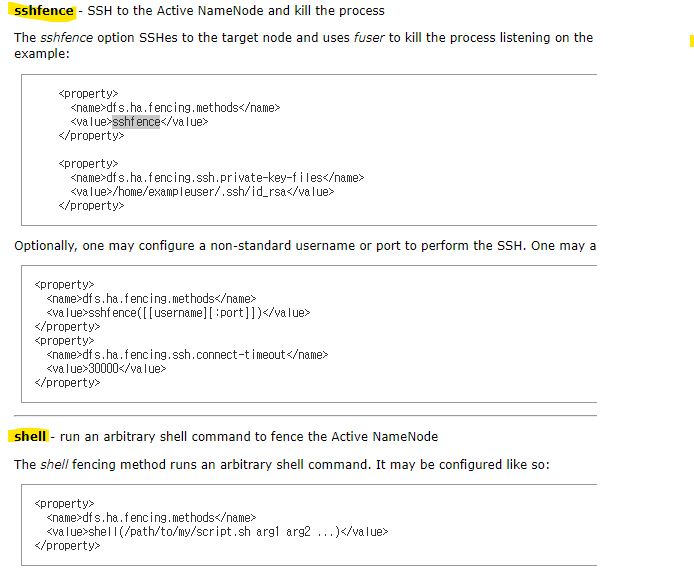
fencing ?
--> active 노드에서 장애발생으로 standby 가 active 로 전환될 때,
그 찰나에 active 노드의 장애가 해결되어 다시 정상으로 돌아와 active 중복이 되는 상황을 막기 위해
장애복구컨트롤러(failover) 가 기존 active 노드를 확실히 죽인다.
Namenode 를 HA 구성하여 SPOF(Single Point Of Failure)에서 벗어났지만,
이번엔 리소스관리자인 YARN이 또다른 SPOF입니다.
Resource Manager를 HA 구성해야 합니다.
참고 : https://tdoodle.tistory.com/entry/Hadoop-Resource-Manager-HA-%EA%B5%AC%EC%84%B1%ED%95%98%EA%B8%B0
Hadoop Resource Manager HA 구성하기
Namenode 를 HA 구성하여 SPOF(Single Point Of Failure)에서 벗어났지만, 이번엔 리소스관리자인 YARN이 또다른 SPOF입니다. 이번에는 Resource Manager를 HA 구성하는 방법에 대하여 알아보겠습니다. 1. 서버 구성
tdoodle.tistory.com
- framework.name : yarn 을 사용하겠다.
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/hadoopdata/yarn/nm-local-dir</value>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>/home/hadoop/hadoopdata/yarn/system/rmstore</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>0.0.0.0:8089</value>
</property>
<!-- for Resource Manager HA configuration -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop02:8088</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
- yarn.nodemanager.aux-services 속성은 mapreduce.shuffle이라는 보조 서비스를 사용할지를 노드매니저에 알려준다. 보조 서비스를 구현하는 노드매니저에 전달한 후, 서비스를 구현하는 수단으로서 클래스 이름을 전달한다. 이런 특정 설정을 통해 어떤 방식으로 셔플이 일어날지를 맵리듀스에게 알려준다. 기본적으로 비 맵리듀스 잡에 대해서는 노드매니저가 데이터를 셔플하지 않기 때문에, 맵리듀스 서비스를 설정할 필요가 있다.
- yarn.resourcemanager.recovery.enabled : ResourceManager 시작 시 state 복구 여부
https://bloodguy.tistory.com/entry/Hadoop-YARN-ResourceManager-HA-HighAvailability
[Hadoop] YARN - ResourceManager HA (HighAvailability)
Hadoop 2.X 부터 NameNode가 HA를 통해 SPOF(SinglePointOfFailure)에서 벗어났지만, YARN의 ResourceManager는 새로운 SPOF 였음. 하지만 Hadoop 2.4 부터 ResourceManager HA가 도입됨에따라 Hadoop은 이제 SPOF가 완전히 제거된
bloodguy.tistory.com
* 중요 yarn 데몬 속성
속성명
종류
기본값
설명
yarn.resourcemanager.hostname
호스트명
0.0.0.0
리소스 매니저가 수행된 머신의 호스트명.
yarn.resourcemanager.address
호스트명과 포트
호스트네임:8032
리소스 매니저의 RPC 서버( 클라이언트 애플리케이션에서 서버 애플리케이션으로 함수를 호출하는 방식 ) 가 동작하는 호스트명과 포트
yarn.nodemanager.local-dirs
콤마로 분리된 디렉토리명
/nm-local-dir
컨테이너가 임시데이터를 지정하도록 노드매니저가 정한 디렉토리 목록. 애플리케이션 종료 시 데이터가 지워진다.
yarn.nodemanager.aux-services
콤마로 분리된 서비스명
노드 매니저가 수행하는 보조 서비스 목록. 기본적으로 보조 서비스가 지정되지 않는다.
yarn.nodemanager.resource.memory-mb
int
8192
노드 매니저가 수행할 컨테이너에 할당되는 물리 메모리
yarn.nodemanager.vme-pmem-ratio
float
2.1
컨테이너에 대한 가상/물리 메모리 비율. 가상 메모리 사용량은 이 비율에 따라 초과할당 될 수도 있다.
yarn.nodemanager.resource.cpu-vcores
int
0
노드 매니저가 컨테이너에 할당할 수 있는 CPU 코어의 수
yarn.app.mapreduce.am.command-opts
String
애플리케이션 마스터의 힙사이즈
https://wikidocs.net/23575
3-메모리 설정
맵리듀스의 메모리 설정은 mapred-site.xml 파일을 수정하여 변경할 수 있습니다. 기본값은 [mapred-default.xml](https://hadoop.apache…
wikidocs.net
vi hadoop-env.sh
jdk , hadoop 경로 설정