심볼릭 링크 : 파일이나 폴더에 대한 일종의 참조. 심볼릭 링크를 사용하면 파일 시스템 내 서로 다른 두 위치에서 같은 파일에 접근 가능. != 파일/폴더의 복사본 아님. 심볼릭 링크가 폴더를 참조하면 마치 실제 타깃 폴더에 들어온 것처럼 심볼릭 링크의 폴더 내부를 탐색할 수 있음. 변경한 모든 내용은 타깃 폴더에 바로 적용되며, 심볼릭 링크에도 반영됨. ex. vi 로 심볼릭 링크파일 편집 시 타깃 파일 편집한 것과 같음. 두 위치 모두에서 편집내용 확인 가능.
심볼릭 링크에서는 편하게 ex. 자바/ 하둡 형식으로 가능.
----
가상머신에 하둡 설치 시, 사전 준비없이 hadoop fs -ls 명령으로 HDFS 에 접속해 파일 시스템에 쿼리를 수행할 수 있는 것은 가상 머신이 부팅하면서 HDFS 데몬 프로세스를 자동으로 시작했기 때문이다.
start-dfs.sh 로 시작 가능. ---
스파크 커뮤니티는 2개월마다 새로운 버전을 릴리스 할 정도로 활발한데, 여러 버전의 스파크를 관리하고 현재 사용할 버전을 선택할 수 있는 방법 중 하나는
심볼릭 링크 활용 )
이를 사용하면 스파크 버전과 관계없이 모든 스파크 프로그램, 스크립트, 환경 설정 파일에서 스파크 설치 폴더를 참조할 때 항상 지정한 폴더를 사용할 수 있다.
(1) spark shell
스파크를 사용하는 방법은 두 가지다. 1 - 스파크 라이브러리. : 스파크 api를 사용해 스칼라, 자바, 파이썬 독립 프로그램을 작성하는 것. 애플리케이션 코드를 작성하고 스파크에 제출해 실행한 후, 에플리케이션이 파일로 출력한 결과를 분석하는 과정을 거친다. 2 - 스파크의 스칼라 셸 / 파이썬 셸 사용 : 스파크 셸에서 작성한 프로그램은 셸을 종료하면 삭제되므로 주로 테스트/일회성 작업에 사용됨.
PATH에 스파크 bin 디렉토리를 등록해놓으면 spark-shell / pyspark 를 입력해도 스파크 셸을 실행할 수 있다.
(2) log4j
스파크의 오랜 이전 버전에는 콘솔에 INFO 로그가 상세하게 출력되었지만, 최신 버전은 이 문제를 개선했다. 하지만 일부 유용한 로그마저 출력에서 생략해 다소 불편하다.
스파크의 LOG4J 설정을 변경해 스파크 셸에는 오류 로그만 출력하고 나머지 로그들은 추후 문제 진단에 사용할 수 있도록 스파크 루트 폴더의 logs/info.log 파일에 저장해보자. (log4j : 자바의 로깅 라이브러리.)
스파크 셸을 실행하면
출력한 내용 중
Spark context : 스파크 접속하고 세션 설정, 잡 실행관리, 파일 읽기/쓰기 작업 할 수 있다. Spark session
스파크와 교신할 수 있는 일종의 창구이다.
간단 예제) 스파크 API 사용하여 파일 읽어들이고, 줄 개수 세어보기
맨 위의 경로( 루트 디렉토리) 에 테스트 용 파일을 만들어두고, 파일의 전체 줄 개수를 세고, 'dd' 가 등장한 줄만 포함하는 ddLines 컬렉션 새로 만들음.
RDD의 개념
위의 licLines, ddLines 는 마치 평범한 스칼라 컬렉션 같지만, 이는 RDD 라는 스파크 전용 분산 컬렉션이다.
RDD 는 데이터를 조작할 수 있는 다양한 변환 연산자를 제공하지만, 변환 연산자는 항상 새로운 RDD 객체를 생성한다. 즉 한 번 생성된 RDD 는 절대 바뀌지 않는 불변의 성질이 있다.
이는 분산 시스템에서 가장 중요한 장애 내성을 직관적인 방법으로 보장할 수 있다.
RDD 연산자는 크게 변환/행동 두 유형으로 나눈다.
변환 연산자 : RDD의 데이터를 조작해 새로운 RDD를 생성한다. (filter,map 함수) 행동 연산자 : 연산자를 호출한 프로그램으로 계산 결과를 반환하거나 RDD 요소에 특정 작업을 수행하려고 실제 계산을 시작하는 역할을 한다. (count, foreach)
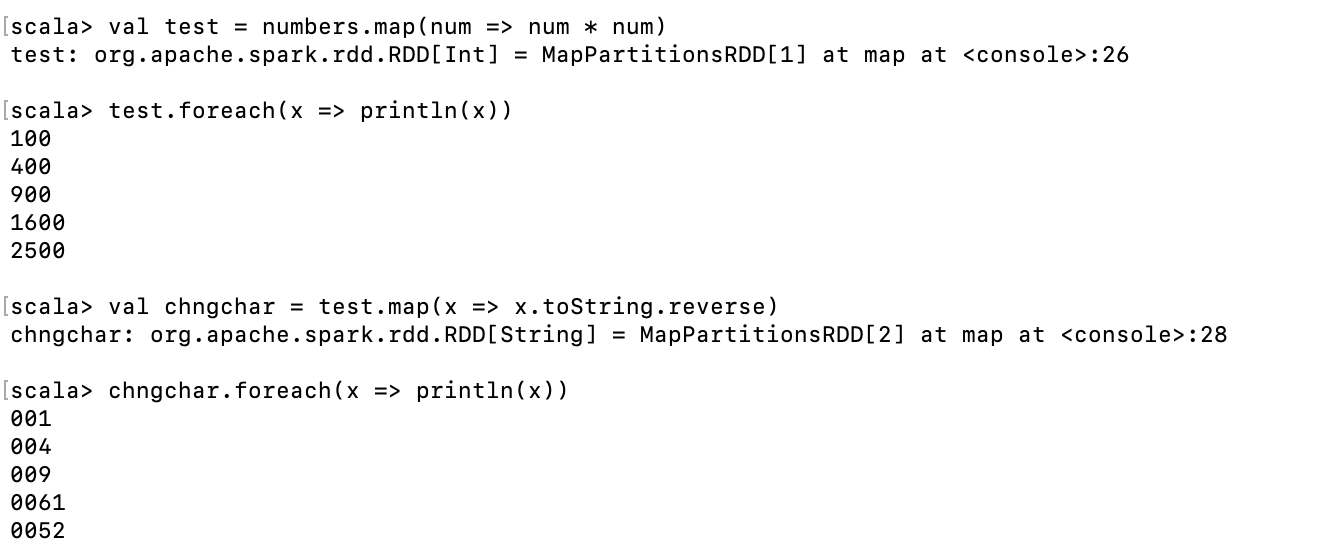
1. map 변환 연산자
parallelize 메서드는 Seq를 받아 Seq 객체의 요소로 구성된 새로운 RDD 를 만든다. (Seq : 스파크의 컬렉션 인터페이스. 이 인터페이스를 구현한 클래스에는 Array 나 List 등이 있다.)
이 Seq 객체의 요소는 여러 스파크 실행자로 분산된다. parallelize 메서드는 makeRDD 라고 alias 로 호출할 수 있다.
하둡은 빅데이터를 처리하기 의해 고안됐다. 기업들이 하둡으로 처리하고 있는 데이터에는 클릭 스트림 데이터, 서버 로그, 세그먼트 데이터, 비정형 데이터, 지리적 데이터 등등이 있다.
하둡의 핵심 능력은 '데이터 지역성' 이다. : 데이터가 저장되는 곳에서 데이터를 프로세싱
하둡은 HDFS 에 데이터를 저장하고 얀(하둡 리소스 관리 시스템)을 사용해 맵리듀스 프로세싱을 클러스터의 노드로 이동한다. 이런 맥락으로 보면 분산 파일 시스템은 데이터를 네트워크를 통해 분산 저장하고 관리하는 파일 시스템이라고 볼 수 있다.
HDFS 스케일 아웃 방식을 사용한다 - 데이터 사이즈가 커질수록 서버를 추가해 전체적인 저장능력을 증가시키는 방식
* 클러스터 컴퓨팅
클러스터 모델을 사용하는 이유는 큰 스케일의 데이터를 처리하는 것에 있다. 때문에 각각의 노드에서 실패한 작업을 단순히 실행하는 것은 의미가 없다.
* 하둡 클러스터들
: 하둡이 실행되는 머신들과 그 머신이 데이터를 저장하고 프로세싱하도록 하는 운영 시스템인 데몬, 소프트웨어 프로세스들로 구성된다. 구성 : -하둡 프레임워크를 운영하는 데몬이 실행될 마스터 노드 -HDFS와 프로세싱을 담당하는 워커 노드들 -엣지 서버들 -> 하둡 클러스터에 접근하는 애플리케이션을 실행한다. - 관계형 DB (하이브,스쿱,우지,휴 같은 프레임워크의 메타데이터 저장) - 카프카, 스톰같은 특정 프레임워크를 위한 전용 서버들
하둡은 백그라운드에서 실행되는 일련의 데몬 프로세스들을 통해 스토리지와 프로세싱 역할을 수행한다. 리눅스 시스템에서 이런 데몬은 독립적인 JVM 내에서 동작한다.
클러스터의 노드 종류
1. 마스터 노드 : 클러스터의 작업을 중재한다. CLIENT들은 컴퓨팅을 하기 위해 마스터노드에 접속한다. 각각의 클러스터는 클러스터 크기에 따라 3~6개 정도로 소수의 마스터 노드들을 구성한다. 2. 워커 노드 : 마스터 노드의 지시에 따라 명령을 수행한다. 대부분의 클러스터 노드들은 워커 노드에 해당한다. 실제로 데이터가 저장되고 프로세싱하는 노드이다.
* 하둡이 효과적인 가장 큰 이유는 데이터를 네트워크로 이동하지 않는다. 프로세싱을 하는 노드로 데이터를 이동하는 대신 데이터가 저장된 노드에서 프로세싱한다. 우리는 HDFS 데이터가 저장된 노드로 작업 스케쥴을 조정할 수 있다. 이렇게 하면 네트워크 부담을 줄이고 I/O를 주로 로컬 디스크, 또는 같은 렉으로 제한할 수 있다.
* 하둡 컴포넌트, 하둡 생태계
기본 컴포넌트 위에 다른 컴포넌트를 추가할 수 있다. (EX. 하이브, 피그, 카프카, 스쿱 등) 컴포넌트를 추가하면, 하둡에 저장된 데이터를 처리하고 다른 데이터들과 통합할 수 있다.
** 하둡을 관리하는 것이 무엇인가?
* 하둡 관리
하둡은 장애허용 시스템이다. 하나의 물리적인 디스크나 시스템 전체가 잘못되더라도 실행하고 있는 job 을 망치지 않는다. 스토리지 문제로 인한 오류라면 하둡이 자동으로 다른 노드에서 같은 job 을 실행하기 때문이다.